Consistent Hashing
Distributing keys across nodes so adding or removing one reshuffles as little as possible.
When you distribute data across N servers using hash(key) % N, adding or removing a single server forces you to remap almost every key. Consistent hashing solves this by arranging both servers and keys on a virtual ring — a server change only remaps the keys that were assigned to that server, leaving everything else untouched.
01The problem with modulo hashing
The naive approach assigns key to server hash(key) % N. This works fine when N is fixed, but in distributed systems servers come and go. When you add a server (N becomes N+1), every key whose hash % (N+1) differs from its hash % N must move. On average that's (N/(N+1)) of all keys — close to 100%. In a cache cluster, this means a cache miss storm and a potential thundering herd on your database.
02The hash ring
Consistent hashing maps both servers and keys to the same circular space (typically [0, 2³²)). To place a server, hash its name or IP to a point on the ring. To find which server owns a key, hash the key to a point on the ring and walk clockwise until you hit a server. When a server is added, only the keys between it and its counter-clockwise neighbor need to move. When a server is removed, its keys fall through to the next clockwise server.
Ring: 0 -------- ServerA(200) ---- ServerB(500) ---- ServerC(800) ---- 2³²
Key X hashes to 350 → walks clockwise → lands on ServerB
Key Y hashes to 650 → walks clockwise → lands on ServerC
Key Z hashes to 900 → walks clockwise → wraps around → lands on ServerA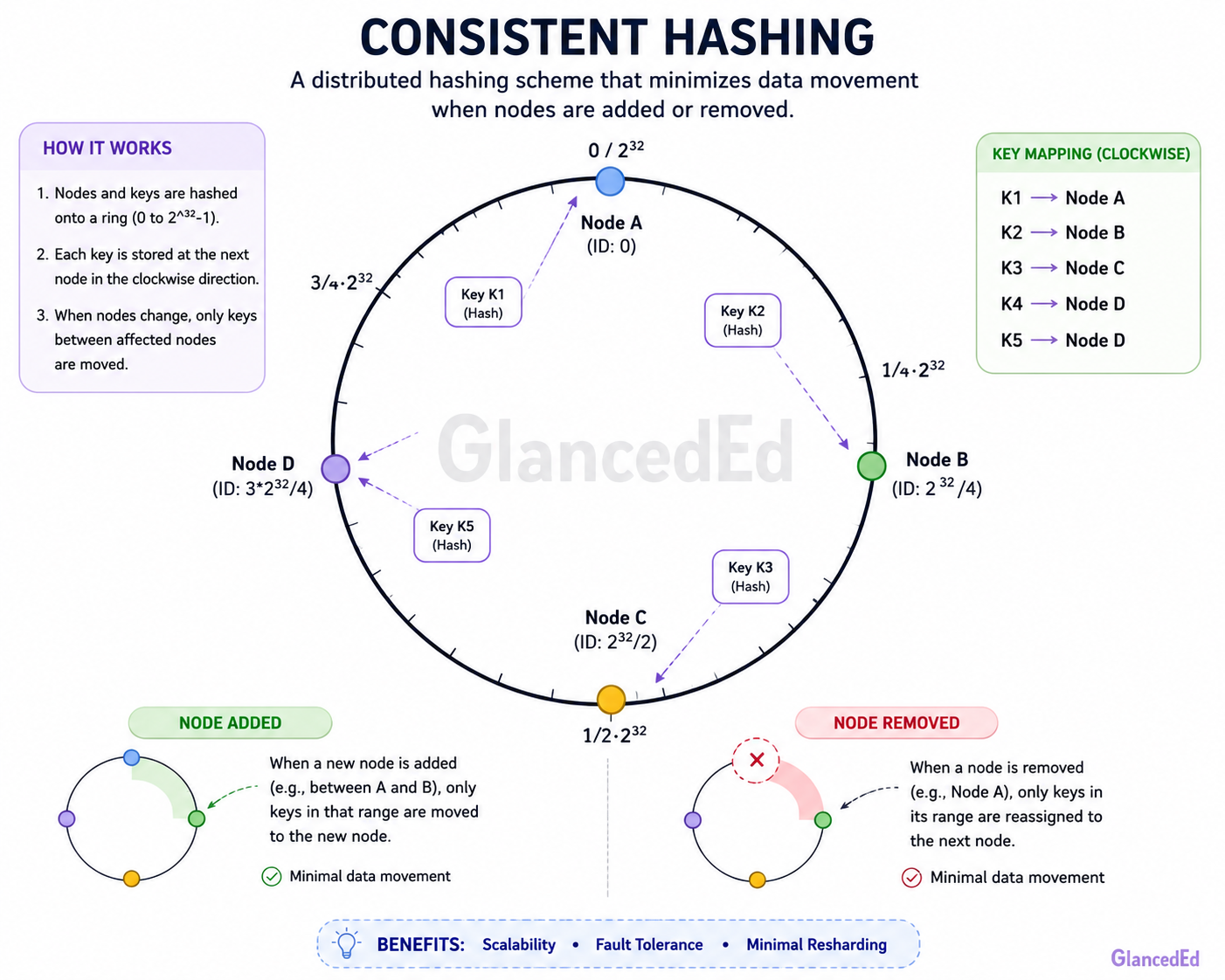
03Virtual nodes for even distribution
With few servers, the ring can be badly unbalanced — one server might own 60% of the key space and another only 10%. Virtual nodes fix this: instead of placing each server at one ring position, place it at K positions (e.g., K=150). The load each server handles is now the sum of K small, randomly distributed arcs, which converges to 1/N of total load. When a server is removed, its virtual nodes' keys spread across all remaining servers rather than piling onto one.
04Where it is used in practice
Amazon DynamoDB and Apache Cassandra use consistent hashing (with virtual nodes) for distributing data partitions. Memcached client libraries use it to decide which cache server to talk to. Content delivery networks use it to route requests to edge nodes. The key insight that makes it practical: you can add or remove capacity incrementally with minimal disruption — no full reshuffling, no downtime for key migration.